UA5 — Engenharia Reversa e Normalização
Como reconstruir modelos de BD sem documentação e como as quatro formas normais eliminam redundâncias e anomalias.
Engenharia reversa em banco de dados
A engenharia reversa de banco de dados é usada quando a documentação de um BD não existe ou está desatualizada. A partir de arquivos, documentos ou do próprio banco, ela reconstrói os modelos conceituais e lógicos que deveriam existir.
Quando aplicar:
- O BD não tem modelo ER ou diagrama;
- O modelo existe, mas não foi atualizado após alterações;
- Um sistema precisa migrar de um SGBD não relacional para um relacional;
- Um projeto de reengenharia total de sistema começa pela análise dos dados existentes.
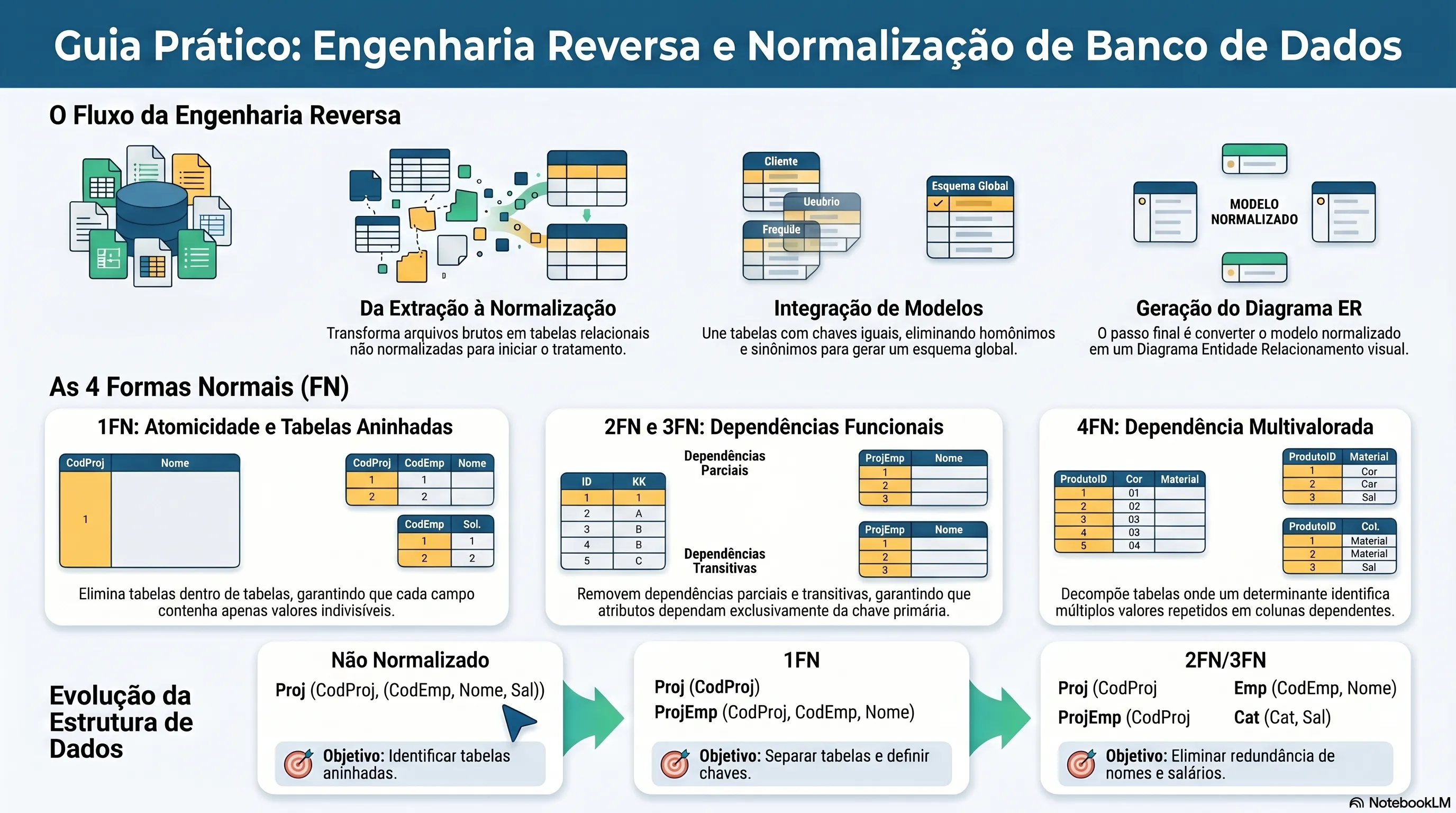
O processo parte dos arquivos brutos e avança em direção ao modelo ER final:
| Etapa | O que acontece |
|---|---|
| 1. Descrição do arquivo | Levantamento das estruturas de dados disponíveis (documentos, arquivos manuais, BD não relacional). |
| 2. Representação como tabela ÑN | Os dados são representados como tabelas relacionais ainda não normalizadas. |
| 3. Normalização | As tabelas passam pelas formas normais (1FN a 4FN) para eliminar redundâncias e garantir integridade. |
| 4. Integração de modelos | Os modelos normalizados de cada arquivo são unificados em um esquema relacional global. |
| 5. Transformação em ER | O esquema relacional integrado é convertido em modelo e diagrama ER (DER). |
| 6. Eliminação de redundâncias | O DER final é revisado para remover informações duplicadas entre entidades. |
Normalização
Normalização é o processo de aplicar formas normais a um esquema relacional para garantir que as tabelas sejam bem projetadas — sem redundâncias, sem anomalias e com integridade dos dados.
A forma normal é uma regra que uma tabela precisa obedecer para ser considerada “bem projetada”. As primeiras quatro formas normais são as mais utilizadas na prática da engenharia reversa.
1FN — Primeira Forma Normal: atomicidade
Regra: todos os atributos devem conter apenas valores atômicos (indivisíveis). Nenhuma tabela pode ter tabelas aninhadas — conjuntos de valores como valor de atributo são proibidos.
Exemplo: dado o esquema não normalizado abaixo (tabela Proj com tabela Emp aninhada):
Proj (CodProj, Tipo, Descr,
(CodEmp, Nome, Cat, Sal, DataIni, TempAl))A passagem para 1FN por decomposição cria tabelas separadas:
1FN
Proj (CodProj, Tipo, Descr)
ProjEmp (CodProj, CodEmp, Nome, Cat, Sal, DataIni, TempAl)A chave primária de ProjEmp é composta — (CodProj, CodEmp) — porque o mesmo empregado pode trabalhar em mais de um projeto.
Dependência funcional
Antes de avançar para 2FN e 3FN, é necessário entender dependência funcional (DF): a coluna A determina a coluna B (A → B) quando cada valor de A está sempre vinculado ao mesmo valor de B.
Exemplo: CodEmp → Sal — o código do empregado determina seu salário; conhecendo o código, sabe-se o salário. O CodEmp é o determinante dessa DF.
2FN — Segunda Forma Normal: sem dependência parcial
Regra: além de estar na 1FN, todas as colunas não-chave devem depender da chave primária completa — não de apenas parte dela.
Isso só é relevante quando a chave primária é composta. Em ProjEmp (CodProj, CodEmp, Nome, Cat, Sal, DataIni, TempAl):
Nome,CateSaldependem apenas deCodEmp— são dependências parciais;DataInieTempAldependem de(CodProj, CodEmp)— dependem da chave completa.
A 2FN elimina as dependências parciais criando tabelas novas:
2FN
Proj (CodProj, Tipo, Descr)
ProjEmp (CodProj, CodEmp, DataIni, TempAl)
Emp (CodEmp, Nome, Cat, Sal)3FN — Terceira Forma Normal: sem dependência transitiva
Regra: além de estar na 2FN, nenhuma coluna não-chave pode depender de outra coluna não-chave. As colunas devem depender exclusivamente da chave primária.
Em Emp (CodEmp, Nome, Cat, Sal): o salário (Sal) depende da categoria (Cat), que por sua vez depende de CodEmp. Isso é uma dependência transitiva: CodEmp → Cat → Sal.
A 3FN elimina essa dependência extraindo a relação para uma nova tabela:
3FN
Proj (CodProj, Tipo, Descr)
ProjEmp (CodProj, CodEmp, DataIni, TempAl)
Emp (CodEmp, Nome, Cat)
Cat (Cat, Sal)4FN — Quarta Forma Normal: sem dependência multivalorada
Regra: além de estar na 3FN, não pode haver dependência funcional multivalorada — situação em que um valor de uma coluna determina múltiplos valores em outra coluna da mesma tabela.
Exemplo: tabela Utilização (CodProj, CodEmp, CodEquip) em que as três colunas compõem a chave primária. O valor de CodProj determina múltiplos valores de CodEmp e também múltiplos valores de CodEquip — de forma independente entre si.
A 4FN decompõe a tabela em duas:
4FN
ProjEmp (CodProj, CodEmp)
ProjEquip (CodProj, CodEquip)Integração de modelos
Após normalizar todos os arquivos do sistema individualmente, os esquemas resultantes precisam ser integrados em um modelo global. O processo tem três passos:
-
Integração de tabelas com chaves primárias iguais — quando dois documentos têm tabelas com a mesma chave primária, domínio e valores coincidentes, elas são fundidas em uma só. Conflitos de nome (homônimos ou sinônimos) são resolvidos por renomeação.
-
Integração de tabelas com chave contida — quando uma tabela tem apenas colunas que já são subconjunto da chave de outra tabela (com mesmos valores), a menor é redundante e pode ser eliminada sem perda de informação.
-
Verificação de 3FN — após fundir tabelas, verificar se o resultado ainda obedece a 3FN. A integração pode reintroduzir dependências transitivas.
Anomalias em bancos de dados
A redundância de dados em um BD mal normalizado causa três tipos de anomalias:
| Anomalia | Como ocorre |
|---|---|
| Atualização | Um dado redundante é atualizado em parte das linhas; as outras ficam com o valor antigo, gerando inconsistência. |
| Inserção | Para inserir um registro, é necessário inserir dados relacionados que ainda não existem, ou inseri-los de forma incompleta. |
| Exclusão | Ao remover um registro, informações relacionadas que dependem dele são perdidas junto. |
Limitações do modelo ER resultante da engenharia reversa:
- Omissão de chaves primárias — documentos convencionais podem não incluir o campo identificador interno do sistema; pode ser necessário usar outro atributo como chave (ex.: CPF).
- Atributos implícitos — a ordem de registros em um arquivo pode representar um atributo não declarado (ex.: ordem de classificação). Esse atributo precisa ser explicitado no esquema.
- Atributos irrelevantes — campos técnicos como contadores de ocorrências ou tamanhos de campos devem ser eliminados antes da 1FN.
A normalização reduz redundâncias e anomalias, mas não garante um modelo ER perfeito. O último passo da engenharia reversa é sempre revisar manualmente o DER gerado e corrigir problemas restantes.
Material com referências de 2009–2011. O conteúdo conceitual de normalização (1FN–4FN) é atemporal e válido. Porém, o livro base (Heuser, 2009; Ramakrishnan & Gehrke, 2011) usa MySQL Workbench como única ferramenta de modelagem e não menciona alternativas modernas. A BCNF (Forma Normal de Boyce-Codd), uma extensão refinada da 3FN, não é abordada. Processos de engenharia reversa hoje são amplamente assistidos por ferramentas que automatizam parte do trabalho.
Práticas Modernas
- Ferramentas de engenharia reversa automatizada — DBeaver, pgAdmin, MySQL Workbench e DataGrip conseguem gerar o diagrama ER diretamente a partir de um banco existente, lendo os metadados do SGBD (chaves, índices, FKs).
- BCNF (Boyce-Codd Normal Form) — refinamento da 3FN que resolve casos em que há múltiplos candidatos a chave primária com dependências entre si. É mais restritiva que a 3FN e é exigida em alguns projetos críticos.
- dbdiagram.io e DBML — permitem escrever o esquema relacional em texto e gerar o diagrama visualmente; facilitam revisão colaborativa e versionamento no git.
- Migrations como documentação viva — em vez de manter diagramas estáticos, equipes modernas usam arquivos de migration (Flyway, Liquibase, Prisma Migrate, Laravel Migrations) que registram cada alteração incremental no esquema, tornando a engenharia reversa parcialmente desnecessária quando bem aplicada desde o início.
- Normalização pragmática — em bancos analíticos (data warehouses), a desnormalização intencional é comum para otimizar leitura. Modelos como Star Schema e Snowflake Schema violam deliberadamente as formas normais em favor do desempenho de consultas analíticas.
- ORMs e schema introspection — ferramentas como Prisma, Sequelize e SQLAlchemy conseguem introspectar um banco existente e gerar o schema de código automaticamente, acelerando a engenharia reversa em projetos de integração.
Dicas para a Prova
- A engenharia reversa de BD parte dos arquivos brutos e segue de baixo para cima: descrição → tabela ÑN → normalização → integração → ER → DER.
- 1FN elimina tabelas aninhadas (valores não atômicos). 2FN elimina dependência parcial (coluna depende de parte da chave composta). 3FN elimina dependência transitiva (coluna não-chave depende de outra não-chave). 4FN elimina dependência multivalorada.
- A 2FN só é violada quando a chave primária é composta — tabelas com chave simples estão automaticamente na 2FN.
- Na questão 3 do PDF: a 2FN elimina dependência parcial; a 4FN elimina dependência multivalorada — não confundir.
- Integração de modelos funde tabelas com mesma PK e domínio; elimina tabelas cuja chave é subconjunto da chave de outra tabela com mesmos valores.
- Três anomalias causadas por redundância: atualização (inconsistência), inserção (dados incompletos) e exclusão (perda de dados relacionados).
- Após a integração, sempre verificar se as tabelas resultantes ainda obedecem à 3FN.
Referências
- HEUSER, C. A. Projeto de banco de dados. 6. ed. Porto Alegre: Bookman, 2009.
- RAMAKRISHNAN, R.; GEHRKE, J. Sistemas de gerenciamento de banco de dados. 3. ed. Porto Alegre: AMGH, 2011.
- ELMASRI, R.; NAVATHE, S. B. Sistemas de banco de dados. 6. ed. São Paulo: Pearson, 2011.
- DATE, C. J. Introdução a sistemas de banco de dados. 8. ed. Rio de Janeiro: Elsevier, 2003.