UA2 — Arquitetura de Banco de Dados
A arquitetura de um banco de dados define como o SGBD é instalado e como os dados são estruturados. Esta UA cobre as arquiteturas de dados, os modelos de BD (relacional, NoSQL e outros), os esquemas ANSI/SPARC, os principais SGBDs do mercado e os perfis de usuários.
O que é um SGBD
Um Sistema Gerenciador de Banco de Dados (SGBD) é um conjunto de softwares que oferece serviços de criação e manipulação de bancos de dados. Ele facilita a definição, construção, manipulação e compartilhamento de dados, protegendo a integridade e controlando acessos simultâneos.
Um banco de dados é uma coleção de dados relacionados que representa aspectos do mundo real — o chamado minimundo ou universo de discurso. Toda mudança relevante no mundo real deve ser refletida no banco.
Os SGBDs podem ser classificados de três formas: pela arquitetura de dados, pelo modelo de dados e pelos tipos de dados que suportam.
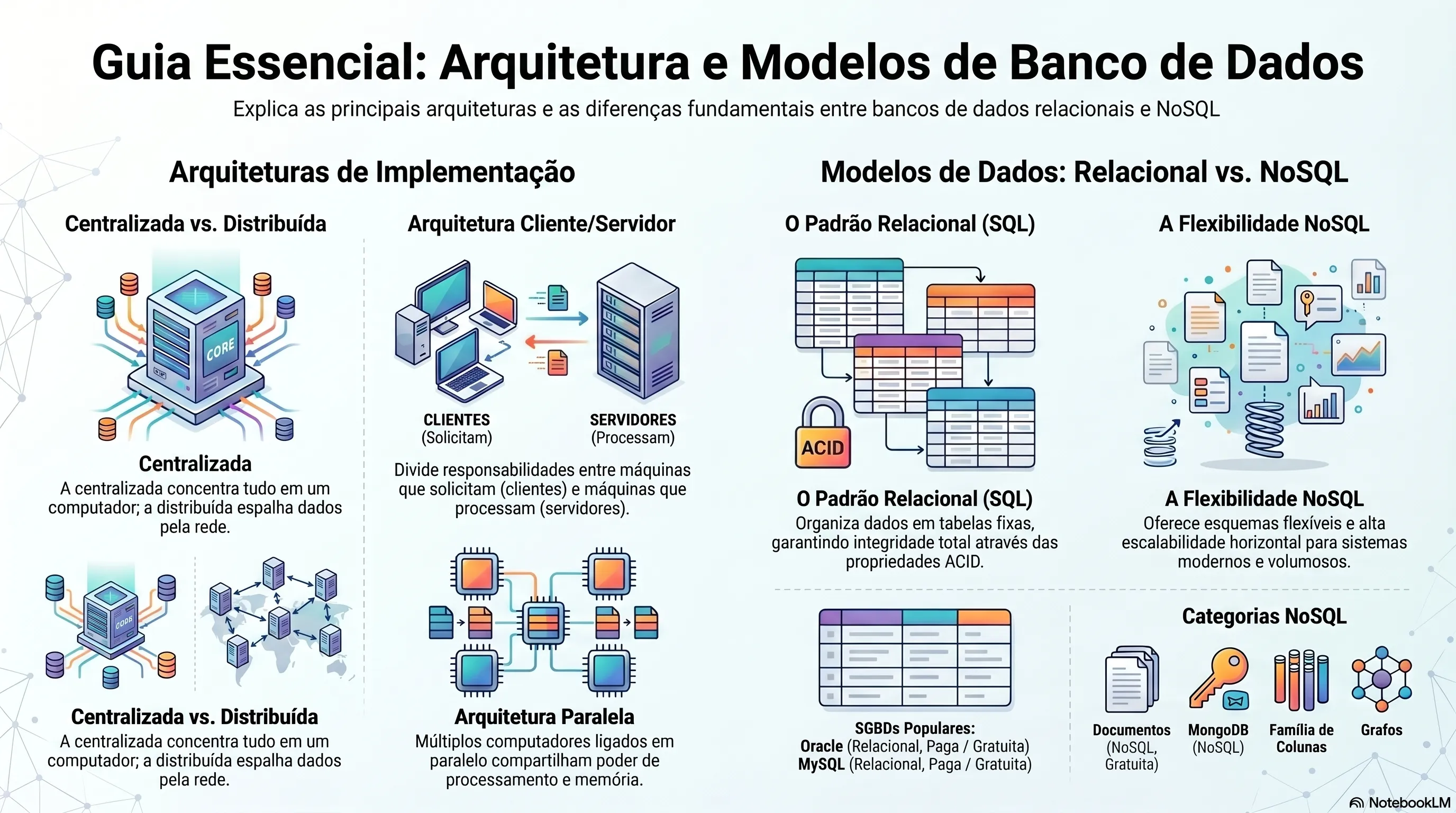
Arquiteturas de dados
A arquitetura do banco de dados sofre grande influência do sistema computacional onde o SGBD está instalado. As arquiteturas mais comuns são:
| Arquitetura | Descrição |
|---|---|
| Centralizada | Processamento principal em um único computador; usada quando não há recursos para múltiplos servidores |
| Cliente/servidor | Divide responsabilidades entre clientes e servidor(es); o mais comum no mercado |
| Paralela | Vários computadores físicos em paralelo compartilham processamento, I/O, armazenamento e memória; logicamente semelhante à centralizada |
| Distribuída | BD e aplicações espalhados pela rede em diferentes computadores |
Na arquitetura cliente/servidor em três camadas:
- Servidor de BD: SGBD + banco de dados
- Servidor de aplicação: regras de negócio e acesso ao SGBD
- Máquinas cliente: interface e pequenos processamentos locais
Modelos de dados
Hierárquico
O primeiro tipo de BD de que se tem notícia. Organiza os dados em estrutura de árvore com registros pai e filho. Um filho só pode ter um pai.
Rede (CODASYL/DBTG)
Semelhante ao hierárquico, mas um registro pode ter múltiplos pais. As estruturas fundamentais são registros e conjuntos (sets).
Relacional
O mais popular. Criado em 1985 por Edgar Frank Codd. Os dados ficam em tabelas (relações) com linhas e colunas:
- Tabela (relação): estrutura de linhas e colunas; define a lógica entre os dados
- Registro (tupla/linha): referência aos atributos da tabela; pode ter valores nulos se permitido
- Atributo (coluna): identifica e caracteriza os dados de uma coluna
Premissas do modelo relacional: integridade referencial, operações de inserção/alteração/remoção em alto nível, acesso via consulta às tabelas.
Exemplos: Oracle, MySQL, SQL Server, MariaDB, PostgreSQL.
Orientado a objetos
Armazena dados na forma de objetos — similar ao conceito das linguagens OO, como Java. Usado quando o modelo relacional se torna complexo demais para o tipo de dado. Os objetos só são acessados pelos métodos predefinidos e podem referenciar outros objetos.
Objeto-relacional
Mescla as características do relacional e do orientado a objetos. Armazena em tabelas, mas converte tuplas em objetos imediatamente. Suporta SQL.
Exemplo: PostgreSQL.
Semiestruturado
Sem estrutura rígida; usa marcações para organizar dados. Não possui linguagem de consulta padrão.
NoSQL (not only SQL)
Surgiu em 1998 como alternativa para cenários em que o modelo relacional não tem desempenho adequado (ex.: alto volume, alta escalabilidade). Não tem o objetivo de substituir o modelo relacional.
Não apresenta linguagem de consulta padrão entre os diferentes tipos.
| Categoria | Descrição | Exemplos |
|---|---|---|
| Família de colunas | Dados mapeados por chaves formando um mapa | BigTable, Cassandra |
| Documentos | Armazena documentos com chave de identificação | MongoDB, CouchDB |
| Chave-valor | Guarda um valor e cria uma chave de referência | Amazon Dynamo |
| Grafos | Nodos (entidades) conectados por arestas (relações) | InfoGrid, Neo4j |
Esquemas de banco de dados — Arquitetura ANSI/SPARC
A arquitetura de três esquemas separa o usuário da aplicação do banco de dados físico:
| Nível | Esquema | Descrição |
|---|---|---|
| Interno | Físico | Descreve a estrutura de armazenamento físico e os caminhos de acesso ao banco |
| Conceitual | Lógico global | Descreve toda a estrutura do BD para os usuários; oculta detalhes físicos; foca em entidades, tipos de dados, relacionamentos e restrições |
| Externo | Visão do usuário | Descreve a parte do BD que determinado grupo tem interesse; oculta o restante |
Tipos de dados suportados pelos SGBDs
| Tipo | Descrição |
|---|---|
| Dados clássicos | Valores numéricos e textuais |
| Textos/documentos | Dados em formato de texto ou documento; normalmente XML |
| Dados multimídia | Imagens, PDFs etc. |
| Dados geográficos | Pontos, linhas e polígonos para representações espaciais |
Níveis de abstração
- Alto nível (conceitual): conceitos que descrevem os dados como percebidos pelos usuários — entidades, atributos, relacionamentos
- Baixo nível (físico): formato dos registros, ordem, disposição e rotas de acesso
- Representacional (implementação): nível intermediário; oculta detalhes físicos mas é interpretável pelos usuários finais; inclui o modelo relacional
Principais SGBDs do mercado
| SGBD | Licença | Arquitetura | Modelo |
|---|---|---|---|
| Oracle | Paga e gratuita | Cliente/servidor | Relacional |
| MySQL | Paga e gratuita | Cliente/servidor | Relacional |
| Microsoft SQL Server | Paga e gratuita | Cliente/servidor | Relacional |
| PostgreSQL | Gratuita | Cliente/servidor | Objeto-relacional |
| MariaDB | Gratuita | Cliente/servidor | Relacional |
| Firebird | Gratuita | Cliente/servidor | Relacional |
| IBM DB2 | Paga | Cliente/servidor | Relacional |
| MongoDB | Gratuita | Distribuída | Documentos |
| Cassandra | Gratuita | Distribuída | Família de colunas |
| Redis | Gratuita | Distribuída | Chave-valor |
Destaques:
- Oracle, MySQL e SQL Server lideram em popularidade de mercado
- PostgreSQL é considerado por muitos o melhor BD open source; muito usado em sistemas web
- MariaDB surgiu a partir do MySQL em 2009, com foco em simplicidade e segurança
- Cassandra foi criado pelo Facebook, tornado open source em 2008; mantido pela Apache; escala sem perda de performance
- MongoDB une características relacionais e NoSQL; escalabilidade horizontal facilitada
Usuários do sistema de banco de dados
| Perfil | Responsabilidades |
|---|---|
| Projetistas | Identificam os dados a armazenar e definem a estrutura do banco a partir do levantamento de requisitos dos usuários finais |
| Analistas de sistemas | Especificam estrutura e funcionalidades do aplicativo após definir os requisitos |
| Programadores | Desenvolvem a aplicação com base no modelo do projetista e nas especificações do analista; documentam e mantêm o sistema |
| DBA (Administrador de BD) | Gerencia recursos do SGBD; define usuários e níveis de acesso; monitora o sistema; realiza backups e manutenções preventivas |
| Usuários finais | Usam o aplicativo e, por consequência, o banco de dados |
Atenção — dados desatualizados
O quadro de SGBDs e o ranking de popularidade citados no livro são de fevereiro de 2020. O cenário mudou:
- PostgreSQL subiu significativamente e, nas pesquisas de desenvolvedores (Stack Overflow, 2023-2024), é consistentemente o banco mais usado e o mais amado — supera MySQL e SQL Server em preferência
- IBM DB2 e Interbase perderam relevância de mercado
- O MongoDB manteve posição forte, mas o crescimento de PostgreSQL com extensão
pgvectorcomeça a disputar espaço até em casos de uso de IA - SGBDs gerenciados na nuvem (RDS, Aurora, Cloud SQL) dominam novos projetos — a maioria dos quadros de 2020 sequer os menciona
Práticas Modernas
Bancos de dados gerenciados (DBaaS) O modelo atual em empresas é contratar o banco como serviço — o provedor de nuvem cuida de instalação, backups, patches, failover e escalabilidade. O DBA migra de administrador de servidor para arquiteto de dados e otimizador de queries:
| Serviço | Provedor | Base |
|---|---|---|
| Amazon RDS / Aurora | AWS | MySQL, PostgreSQL, MariaDB |
| Cloud SQL | Google Cloud | MySQL, PostgreSQL, SQL Server |
| Azure SQL | Microsoft | SQL Server / PostgreSQL |
| Cosmos DB | Microsoft | NoSQL multi-modelo |
Bancos serverless Escalam automaticamente para zero quando não há tráfego — sem custo ocioso. Exemplos: PlanetScale (MySQL), Neon (PostgreSQL), CockroachDB Serverless. Ideais para projetos com tráfego variável.
NewSQL Bancos que combinam a escalabilidade horizontal do NoSQL com as garantias ACID do relacional. Permitem escalar leituras e escritas em múltiplos nós sem abrir mão de transações consistentes. Exemplos: CockroachDB, TiDB, Google Spanner.
Bancos vetoriais (Vector Databases)
Categoria que explodiu com a IA generativa (2023+). Armazenam embeddings (representações numéricas de texto, imagem, áudio) e permitem busca por similaridade semântica — base de sistemas RAG (Retrieval-Augmented Generation). Exemplos: Pinecone, Weaviate, Qdrant. O PostgreSQL com extensão pgvector também suporta buscas vetoriais.
OLTP vs. OLAP e bancos analíticos SGBDs tradicionais são otimizados para OLTP (transações rápidas, muitas escritas simultâneas). Para análise de grandes volumes, surgiram bancos colunares e analíticos: DuckDB (embedded, OLAP em memória), ClickHouse (OLAP distribuído de alta performance), BigQuery (serverless analytics da Google).
O papel do DBA hoje O DBA moderno trabalha com infraestrutura como código (Terraform para provisionar instâncias de BD), monitoramento de custos de cloud, tuning de queries via ferramentas automatizadas e segurança de dados (criptografia em repouso e em trânsito, controle de acesso granular via IAM).
Dicas para a Prova
- BD chave-valor: Amazon Dynamo — não confundir com MongoDB (documentos) ou Cassandra (família de colunas)
- Arquitetura distribuída: dados e aplicações espalhados em vários computadores pela rede — não confundir com paralela (compartilhamento de recursos com gerência central)
- SGBDs apenas relacionais do quadro: SQL Server, MariaDB e MySQL (MongoDB e Cassandra são NoSQL; PostgreSQL é objeto-relacional)
- A propriedade atomicidade impede que uma operação ocorra pela metade — é característica de transações (ACID), não do BD em si
- Autodescrição: capacidade do SGBD de armazenar informações sobre a própria estrutura — é uma característica válida de sistemas de BD
- Sistemas de arquivos ainda são úteis para determinados tipos de aplicação — BD nem sempre é preferível
- O modelo relacional foi criado por Edgar Frank Codd em 1985
- NoSQL não substitui o modelo relacional — é alternativa para cenários específicos de alto volume ou flexibilidade
- Tuplas (linhas) são compostas de campos, ou seja, valores de atributos
Referências bibliográficas desta UA
- VIDA, E. da S. Banco de Dados. Porto Alegre: SAGAH.
- ELMASRI, R.; NAVATHE, S. B. Sistemas de banco de dados. 6. ed. São Paulo: Pearson, 2010.
- GARCIA-MOLINA, H.; ULLMAN, J. D.; WIDOM, J. Implementação de sistemas de bancos de dados. Rio de Janeiro: Campus, 2001.
- ALVES, W. P. Banco de dados. São Paulo: Érica, 2013.