UA3 — Projeto de BD: criando BD
Um projeto de banco de dados relacional percorre três modelos interdependentes — conceitual, lógico e físico — que transformam requisitos do negócio em tabelas SQL concretas.
Fases do projeto de banco de dados relacional
A construção de um BD relacional segue uma sequência de modelos interdependentes. O resultado de cada fase alimenta a seguinte:
| Fase | O que produz |
|---|---|
| Levantamento e análise de requisitos | Descrição do minimundo — o conjunto de dados que o BD precisará representar |
| Projeto conceitual | Esquema conceitual: entidades, atributos e relacionamentos — independente de SGBD |
| Projeto lógico | Esquema lógico: tabelas, colunas, chaves primárias e estrangeiras — adaptado ao SGBD escolhido |
| Projeto físico | Implementação real: comandos DDL (CREATE TABLE, ALTER TABLE) executados no SGBD |
O processo inverso — reconstruir um modelo conceitual a partir de um BD já existente — é chamado de engenharia reversa. É útil quando a documentação original foi perdida ou o BD evoluiu sem atualização dos modelos.
Modelo lógico — conceitos fundamentais
No modelo lógico, as entidades do modelo conceitual viram tabelas (também chamadas de relações). Cada tabela tem:
- Colunas (atributos / cabeçalhos) — definem quais dados cada linha armazena
- Linhas (tuplas / registros) — os dados propriamente ditos
- Chave primária (PK) — coluna(s) que identificam unicamente cada linha da tabela
- Chave estrangeira (FK) — coluna que referencia a chave primária de outra tabela, criando o relacionamento entre elas
Chave primária — exemplo: numa tabela de alunos com nome, matrícula e CPF, tanto a matrícula quanto o CPF podem servir como chave primária — ambos identificam um aluno de forma única.
Chave estrangeira — exemplo: num BD de empresa com tabelas Colaborador e Departamento, a coluna Codigo_Departamento presente em Colaborador é uma chave estrangeira — ela referencia Codigo_Departamento em Departamento.
Notação de esquema relacional
O esquema relacional descreve as tabelas em texto, com a chave primária sublinhada e as chaves estrangeiras referenciadas explicitamente:
Professor (Cpf, NomeProfessor, Endereco, Sexo, Salario, CodDisciplina, CodT)
CodDisciplina referencia Disciplina
CodT referencia Turma
Disciplina (CodDisc, NomeDisciplina, CpfCoordenador)
Turma (CodTurma, TurmaNome, TurmaSala)Especialização e generalização
- Especialização: dados particulares de um subconjunto de registros. Exemplo: na tabela de clientes, uma empresa tem CNPJ enquanto uma pessoa física tem CPF.
- Generalização: dados comuns a todos os registros. Exemplo: nome, endereço e data de nascimento são genéricos a todos os funcionários.
Projeto lógico com MySQL Workbench
O MySQL Workbench é uma ferramenta visual open source para modelagem de BDs relacionais. Ela permite desenhar o modelo lógico graficamente e exportar o resultado como código SQL (DDL), pronto para execução no MySQL.
Tipos de dados comuns no modelo lógico:
| Tipo | Uso |
|---|---|
int | Valores inteiros (códigos, contadores) |
char(n) | Texto de tamanho fixo n |
varchar(n) | Texto de tamanho variável, até n caracteres |
date | Datas (AAAA-MM-DD) |
Nomes de colunas não podem conter espaços em branco ou hífens em SGBDs relacionais — use abreviações ou
snake_case.
Exemplo — BD “Escola” (professores, disciplinas e turmas):
Professor (Cpf, NomeProfessor, Endereco, Sexo, Salario, CodDisciplina, CodT)
CodDisciplina referencia Disciplina
CodT referencia Turma
Disciplina (CodDisc, NomeDisciplina, CpfCoordenador)
Turma (CodTurma, TurmaNome, TurmaSala)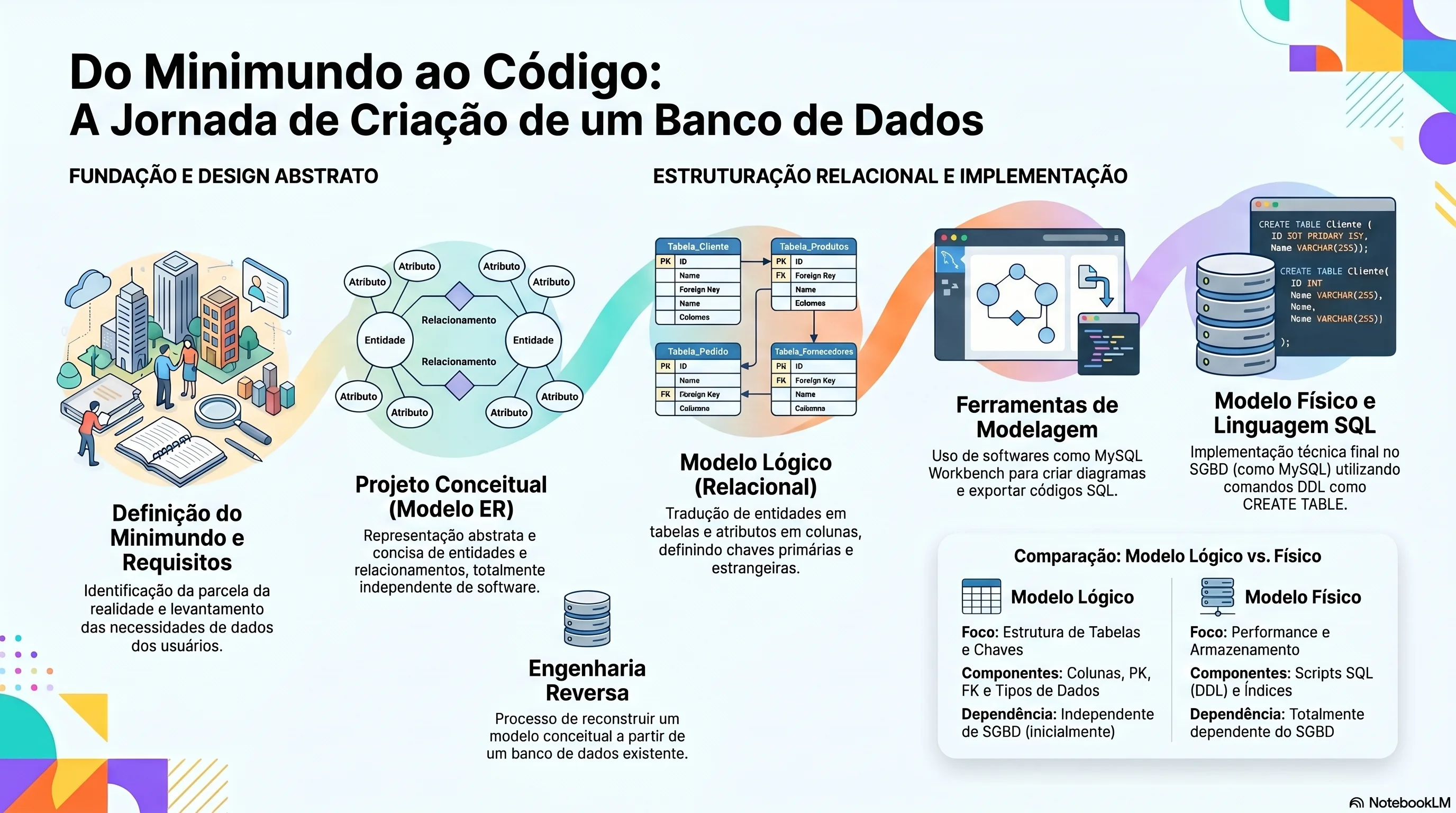
Modelo físico para MySQL
O modelo físico especifica como os dados serão de fato armazenados no SGBD. O Workbench pode exportar o modelo lógico diretamente como código DDL MySQL, gerando os comandos CREATE TABLE e ALTER TABLE.
Estrutura de um CREATE TABLE:
CREATE TABLE `Professor` (
`Cpf` int(10) NOT NULL,
`NomeProfessor` varchar(35) NOT NULL,
`Endereco` varchar(40) NOT NULL,
`Sexo` varchar(10) NOT NULL,
`Salario` int NOT NULL,
`CodDisciplina` int(10) NOT NULL,
`CodT` int(10) NOT NULL,
PRIMARY KEY (`Cpf`)
);
CREATE TABLE `Disciplina` (
`CodDisc` int(10) NOT NULL AUTO_INCREMENT,
`NomeDisciplina` varchar(25) NOT NULL,
`CpfCoordenador` int(10) NOT NULL,
PRIMARY KEY (`CodDisc`)
);
CREATE TABLE `Turma` (
`CodTurma` int(10) NOT NULL AUTO_INCREMENT,
`TurmaNome` varchar(25) NOT NULL,
`TurmaSala` int(5) NOT NULL,
PRIMARY KEY (`CodTurma`)
);Adicionando chaves estrangeiras com ALTER TABLE:
ALTER TABLE `Professor`
ADD CONSTRAINT `Professor_fk0`
FOREIGN KEY (`CodDisciplina`) REFERENCES `Disciplina`(`CodDisc`);
ALTER TABLE `Professor`
ADD CONSTRAINT `Professor_fk1`
FOREIGN KEY (`CodT`) REFERENCES `Turma`(`CodTurma`);AUTO_INCREMENT gera automaticamente um valor inteiro único e crescente para a coluna — útil para chaves primárias que não têm um identificador natural.
NOT NULL garante que a coluna não aceite valores vazios — protege a integridade dos dados.
Atenção — conteúdo desatualizado
O material do livro (2020) foca exclusivamente no MySQL e no MySQL Workbench. O mercado atual é mais diversificado:
- MySQL Workbench ainda é usado, mas ferramentas como DBeaver, DataGrip e pgAdmin são amplamente preferidas — suportam múltiplos SGBDs e têm interfaces mais modernas
- O livro usa apenas MySQL Community; na prática, PostgreSQL é o banco relacional open source mais adotado no mercado e em projetos cloud
AUTO_INCREMENTé sintaxe exclusiva do MySQL; no PostgreSQL o equivalente éSERIALouGENERATED ALWAYS AS IDENTITYint(10)— o número entre parênteses em MySQL não define o tamanho de armazenamento, apenas a largura de exibição; foi depreciado no MySQL 8.0 e removido no 8.0.17+- Projetos modernos raramente executam DDL manual — usam ferramentas de migration (Flyway, Liquibase, Alembic) que versionam e aplicam mudanças de esquema de forma controlada
Práticas Modernas
PostgreSQL como padrão de mercado PostgreSQL é gratuito, open source, altamente compatível com SQL padrão e suportado nativamente em todos os provedores cloud (AWS RDS, Google Cloud SQL, Azure Database):
-- PostgreSQL: chave primária com geração automática
CREATE TABLE professor (
cpf SERIAL PRIMARY KEY,
nome VARCHAR(35) NOT NULL,
cod_disc INT REFERENCES disciplina(cod_disc)
);Convenção snake_case para nomes
Nomes de tabelas e colunas em snake_case são o padrão atual — mais legíveis e sem ambiguidade entre SGBDs:
-- Preferível a: NomeProfessor, CodDisciplina, TurmaSala
nome_professor, cod_disciplina, turma_salaMigrations para versionamento do esquema Em vez de executar DDL manualmente, ferramentas de migration rastreiam e aplicam mudanças de forma auditável:
-- V1__create_escola.sql (Flyway)
CREATE TABLE professor (
cpf SERIAL PRIMARY KEY,
nome VARCHAR(35) NOT NULL
);ORMs e query builders Frameworks como Prisma (Node.js), SQLAlchemy (Python) e Hibernate (Java) geram o esquema e as queries a partir de modelos de código, reduzindo erros de escrita manual de SQL:
# SQLAlchemy (Python)
class Professor(Base):
__tablename__ = "professor"
cpf = Column(Integer, primary_key=True)
nome = Column(String(35), nullable=False)Diagrama ER como documentação viva O modelo conceitual (ER) deve ser mantido atualizado ao longo da vida do projeto — não apenas durante o design inicial. Ferramentas como dbdiagram.io permitem escrever o modelo em texto e gerar o diagrama automaticamente.
Dicas para a Prova
- O processo de construção de um BD relacional segue a ordem: conceitual → lógico → físico — não pule etapas.
- Engenharia reversa é o processo inverso: reconstruir o modelo conceitual a partir de um BD físico já existente.
- Chave primária (PK) identifica unicamente cada linha; chave estrangeira (FK) referencia a PK de outra tabela.
- No esquema relacional, a chave primária é sublinhada; as referências são indicadas com
referencia NomeTabela. CREATE TABLEcria a tabela com colunas e PK;ALTER TABLE ... ADD CONSTRAINT ... FOREIGN KEYadiciona a FK depois.AUTO_INCREMENTgera valores únicos automaticamente — usado em PKs sem identificador natural.NOT NULLimpede que uma coluna receba valores vazios.- Especialização = dados particulares de um subgrupo; Generalização = dados comuns a todos.
- Nomes de colunas não podem ter espaços ou hífens em SGBDs relacionais — use abreviações ou
snake_case. - O minimundo é o recorte do mundo real que o BD representa — apenas os dados relevantes para o sistema.
Referências bibliográficas desta UA
- PICHETTI, R. F. Banco de Dados. Porto Alegre: SAGAH.
- ELMASRI, R.; NAVATHE, S. B. Sistemas de banco de dados. 6. ed. São Paulo: Pearson, 2011.
- HEUSER, C. A. Projeto de banco de dados. 6. ed. Porto Alegre: Bookman, 2009.
- DATE, C. J. Projeto de banco de dados e teoria relacional. São Paulo: Novatec, 2015.
- COSTA, R. L. de C. SQL: guia prático. 2. ed. Rio de Janeiro: Brasport, 2006.